Tags
- hello (1)
- middleman (1)
- s3 (1)
- git (1)
- InfluxDB (5)
- fluentd (2)
- よくわからん (3)
- Elasticsearch (3)
- 勉強会 (2)
- MongoDB (1)
- Sensu (8)
- AWS (10)
- Grafana (2)
- Tasseo (1)
- Shell (1)
- Ruby (4)
- Elastic Beanstalk (1)
- Docker (4)
- ElastiCache (2)
- RDS (2)
- memcached (2)
- twemproxy (2)
- RabbitMQ (3)
- Jq (1)
- Jenkins (1)
- Specinfra (1)
- Serverspec (4)
- Puppet (3)
- Chef (7)
- Graphite (2)
- Infrataster (2)
- mackerel (1)
- Monitoring (3)
- CloudWatch (2)
- Servespec (1)
By year
- 2014 (28)
RabbitMQ のクラスタ構成を体感する
RabbitMQ Sensu Chef Ruby AWSPosted on May 13
はじめに
Sensu や Chef Server でも内部的に使われている RabbitMQ に関してフワッとした知識しかないので自分なりに手を動かして実感してみたい。特にクラスタ構成について興味があるので Ruby で簡単なスクリプトでキューの入出をしながら自分なりの知見を深めてみる。
また、幸い同僚に RabbitMQ に詳しいメンツが揃っているのであまり時間も無いが見聞きしたこともメモっていきたい。
参考
- AMQP 0-9-1 Model Explained
- Clustering Guide
- Highly Available Queues
- Work Queues
- The rabbitmq.config File
クラスタ構成と HA
クラスタ構成と HA についてドキュメントを拾い読みしてみる。英訳等に誤りがあるのでご参考程度に。
RabbitMQ の簡単なイメージ
「百聞は一見に如かず」以下のイメージで RabbitMQ って何をやってるんだというのが掴める(かも)。

上のイメージが掲載されているページの What is AMQP? と Brokers and Their Role も読んでおきたい。
登場人物としては…
- Publishers
- Message brokers
- Consumers
が出てくる。Message brokers がその名の通り仲介役の RabbitMQ になる。そして、Publishers が RabbitMQ にキューを放り込むアプリケーション、そして Consumers がそれを受け取るアプリケーションとなる。そのメッセージのやりとりを AMQP というプロトコルに乗っけて行っている。
一応、自分は RabbitMQ に対しては上記のようなイメージと認識を持っている。今のところこれだけ…すいません。
クラスタ構成
「いきなりクラスタ構成かい!」という自己ツッコミはあるもののクラスタ構成について触れる。
Clustering Guide の冒頭に以下のように書かれている。
A RabbitMQ broker is a logical grouping of one or several Erlang nodes, each running the RabbitMQ application and sharing users, virtual hosts, queues, exchanges, etc. Sometimes we refer to the collection of nodes as a cluster.
RabbitMQ は複数の Erlang ノードで論理的なグルーピングを行いクラスタを構成するようだ。更に以下のように続く。
All data/state required for the operation of a RabbitMQ broker is replicated across all nodes, for reliability and scaling, with full ACID properties.
全てのデータや状態は ACID 特性や信頼性や高可用性の為に全てのノードで複製される。
An exception to this are message queues, which by default reside on the node that created them, though they are visible and reachable from all nodes. To replicate queues across nodes in a cluster, see the documentation on high availability (note that you will need a working cluster first).
例外云々はちょっと端折ってノード間のキュー複製に関しては別のドキュメントがあるようだ。
HA
キューの複製に関してのドキュメントはこちら。かなり端折って(英語力が欲しい)…Configuring Mirroring のセクションを見てみる。
Queues have mirroring enabled via policy. Policies can change at any time;
キューの複製に関しては policy を設定することで有効になるようだ。ポリシーの変更はいつでもオッケーらしい。ほうほう。さらに以下のように続く。
You should be aware of the behaviour of adding mirrors to a queue.
キュー複製の動作に関して動作パターンが複数あるようなニュアンスに取れる。確かにキュー複製に関しては下記の通り複数のポリシーがあるようだ。尚、ポリシーを設定する際には ha-mode というキーとオプションとして ha-params を指定する必要がある。

上記は端折り過ぎているのでこちらに Google 翻訳先生の結果を貼り付けたので合わせて読みたい。
ざっくり言うと…
- ミラーのパターンは 3 パターン
ha-modeがallがクラスタ内のノード全てにコピー(一番、安全)ha-modeがexactlyがクラスタ内の指定した数のノードにコピーha-modeがnodesは指名制(指定したノードにコピー)
また、
Whenever the HA policy for a queue changes it will endeavour to keep its existing mirrors as far as this fits with the new policy.
とあるように HA ポリシーを変更すると、変更後のキューからポリシーが適用されて、それより以前のキューには適用されないようだ(以前の HA ポリシーが適用される)。
RabbitMQ のセットアップ
試した環境は AWS の EC2 インスタンス。さくっと Amazon Linux を利用。一応、自分が以前に書いたこちらも参考にした。
インストールと管理用のプラグインの設定
インストールは以下のように yum で epel を有効にしてインストールするだけ。
sudo yum -y install rabbitmq-server --enablerepo=epel
現在だと rabbitmq-server-3.1.5-1.el6.noarch がインストールされる。
次に管理用のプラグインを有効にする。
sudo /usr/lib/rabbitmq/bin/rabbitmq-plugins enable rabbitmq_shovel
sudo /usr/lib/rabbitmq/bin/rabbitmq-plugins enable rabbitmq_management
sudo /usr/lib/rabbitmq/bin/rabbitmq-plugins enable rabbitmq_shovel_management
rabbitmq_management を有効にするとブラウザの管理コンソールを利用することが出来る。
rabbitmq-server を起動する。
sudo /etc/init.d/rabbitmq-server start
とっても簡単。起動を確認したらあらかじめ rabbitmq-server を止めておく。(起動中に .erlang.cookie の書き換えが良くないぽいので)
sudo /etc/init.d/rabbitmq-server stop
尚、.erlang.cookie 際しては rabbitmq-server を stop しておく必要があるが、クラスタ化のコマンド実行時には rabbitmq-server は動作している必要があるので注意する。
クラスタ化
これも簡単。
まず、/var/lib/rabbitmq 以下の .erlang.cookie をクラスタノード間で同一のものにする。簡単とは言え、これの作業は重要。
cat /var/lib/rabbitmq/.erlang.cookie
自分はマスターとなるノードで上記のように cat したものを適当なファイル名のファイルにコピペして以下のように実行した。(以下の作業はスレーブとなるホストにて実行する)
sudo su -
su - rabbitmq
echo "xxxxxxxxxxxx" > tekito
chmod 600 .erlang.cookie
tr -d '\n' < tekito > .erlang.cookie
chmod 400 .erlang.cookie
次に実際のクラスタ化は以下のように実行する。(以下の作業はスレーブとなるホストにて実行する)
sudo su -
/etc/init.d/rabbitmq-server start
su - rabbitmq
rabbitmqctl cluster_status
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@${master_node_hostname}
rabbitmqctl start_app
これを実行するとブラウザの管理コンソールにて以下のように表示される。2 台のノードでクラスタが構成されるのが解る。
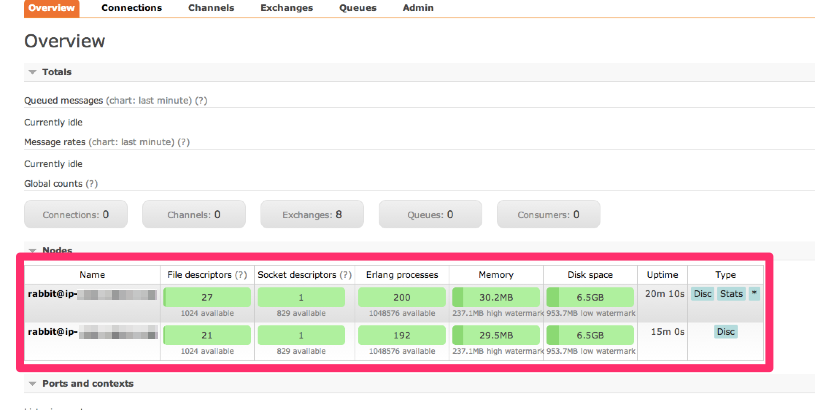
尚、Clustering Guide によると rabbitmq.config に設定を記載することで自動でクラスタが構成されるとある。また、オンプレな環境の場合にはクラスタのノード間で名前解決する手段を設ける必要がある。(DNS または hosts ファイル)
クラスタを体感
クラスタ構成がとれたところでチュートリアルを真似て Ruby からクラスタ構成の RabbitMQ のキューを出し入れしてクラスタ構成を体感してみたい。
ポリシーの設定
HA のポリシーに関しては ha-mode を all で試してみる。
sudo su -
su - rabbitmq
/usr/lib/rabbitmq/bin/rabbitmqctl set_policy all '^.*' '{"ha-mode": "all"}'
Ruby から RabbitMQ を操作(1)
bunny という gem を使うことで簡単に Ruby から RabbitMQ を扱えるようだ。
gem install bunny --version ">= 0.9.1" --no-ri --no-rdoc -V
gem をインストールしたら Publisher 役の send.rb と Consumer 役の receive.rb をそれぞれ作成する。
とりあえず send.rb を実行してみる。

おお、ついでにブラウザの管理画面も…。
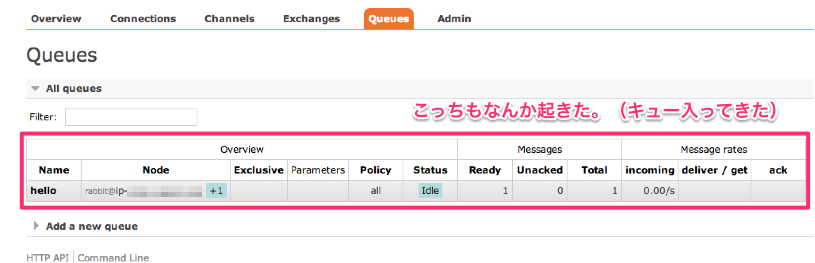
キューがぶっ込まれているのが見える。続けて… recieve.rb を引数無しで実行してみると…

キューを取り出すことが出来ているっぽい。
Ruby から RabbitMQ を操作(2)
キューを取り出したら改めて send.rb を実行してみる。次に recieve.rb を実行するのだが、引数にクラスタ構成のスレーブノードのホスト名を付けて実行してみる。
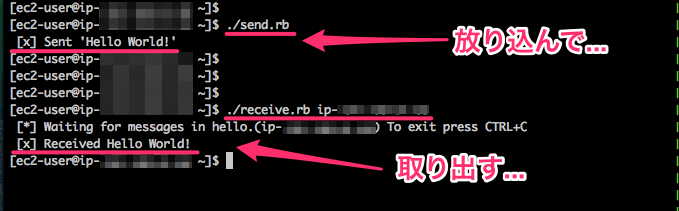
スレーブノードからキューを取り出せた。
おお。
とりあえず…
今日はここまで。
やったこと
- フワッと
RabbitMQについて理解した - ザックリと
RabbitMQのクラスタ構成とHA構成について理解した RubyからRabbitMQにキューを出したり入れたりしたha-modeがallのポリシーでクラスタ構成を体感した
次やること
- 他の
ha-modeの挙動を試しているのはこちら
2014 かっぱのほげふが